
What size does it matter?
Memory requirements are the most obvious advantages of reducing the complexity of the internal load of a model. The bitnet B1.58 model can run using about 0.4GB memory, for other open-weight models of the same parameter size anywhere from about 2 to 5GB.
But the simplified waiting system also leads to more efficient operations with internal operations, with internal operations which depends much more on the simple addition instructions and less on computationally expensive multiplication instructions. Those efficiency reforms means that Bitnet B1.58 uses 85 to 96 percent less energy than similar complete-perfect models, and researchers estimate.
A demo of BITNET B1.58 is running at a speed on Apple M2 CPU.
In particular, using a highly customized kernel designed for bitnet architecture, the bitnet B1.58 model can also run several times faster than the same model running on a standard full-colored transformer. The system “is efficient to reach comparable motion for human reading (5-7 tokens per second)” using a single CPU, writer writes (you can download and run the customized kernels that can run themselves on many hands and X86 CPUs, or try it using this web demo).
Severe, researchers say that these improvements do not come at the cost of performing various benchmark testing arguments, mathematics and “knowledge” abilities (although the claim has not yet been verified independently). Average of results on many general benchmarks, researchers found that Bitnett “offers dramatically better efficiency and acquires almost capabilities with leading models in its size class.”
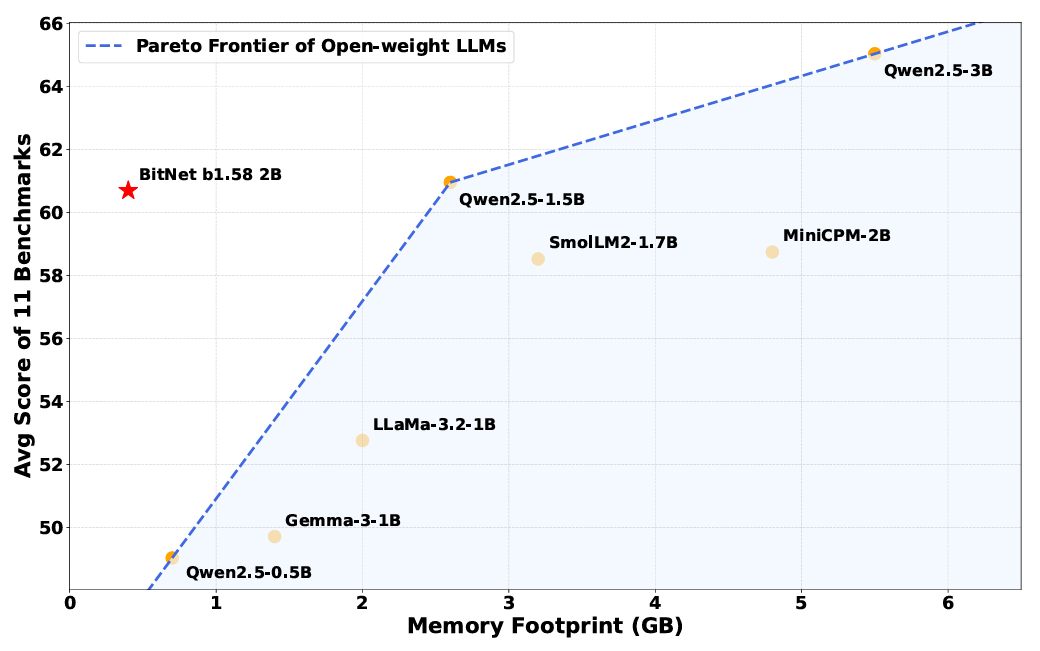
Despite its small memory footprint, Bitnet still performs similar to “complete precision” weighted models on several benchmarks.
Despite its small memory footprint, Bitnet still performs similar to “complete precision” weighted models on several benchmarks.
Despite the obvious success of this “concept of concept” bitnet model, researchers write that they do not understand why the model works as well as it does with such simplified load. He writes, “There is an open area in depth in theoretical underpinning of why 1-bit training is effective on the scale,” they write. And the overall size and reference window of today's largest model also requires more research to get these bitnet models to compete with the “memory”.
Nevertheless, this new research shows a potentially alternative approach to the AI model that are facing splening hardware and energy costs by walking on expensive and powerful GPU. It is possible that today's “complete precision” models are like muscle cars which are wasted too much energy and efforts when a good sub-compact can give equal results equal results.