
An artificial intelligence (AI) technology has been developed to enable camera-based autonomous vehicles to perceive their surroundings more accurately. This innovative approach utilizes the geometric concept of the vanishing point—an artistic device that conveys depth and perspective in images.
Professor Kyungdon Joo and his research team in the Graduate School of Artificial Intelligence at UNIST announced the development of VPOcc, a novel AI framework that leverages the vanishing point to mitigate the 2D–3D discrepancy at both pixel and feature levels. This approach addresses the perspective distortion inherent in camera inputs, enabling more precise scene understanding.
Autonomous vehicles and robots recognize their environment primarily through cameras and LIDAR sensors. While cameras are more affordable, lightweight, and capable of capturing rich color and shape information compared to LIDAR, they also introduce significant issues due to the projection of three-dimensional space onto two-dimensional images. Objects closer to the camera appear larger, while distant objects seem smaller, leading to potential errors such as missed detections of faraway objects or overemphasis on nearby regions.
To address this challenge, the research team designed an AI system that reconstructs scene information based on the vanishing point—a concept established by Renaissance painters to depict depth and perspective, where parallel lines appear to converge at a single point in the distance. Just as humans perceive depth by recognizing vanishing points on a flat canvas, the developed AI model uses this principle to more accurately restore depth and spatial relationships within camera footage.
The VPOcc model consists of three key modules. The first is VPZoomer, which corrects perspective distortion by warping images based on the vanishing point. The second is a VP-guided cross-attention (VPCA), which extracts balanced information from near and far regions through perspective-aware feature aggregation. The third is a special volume fusion (SVF), which fuses original and corrected images to complement each other’s strengths and weaknesses.
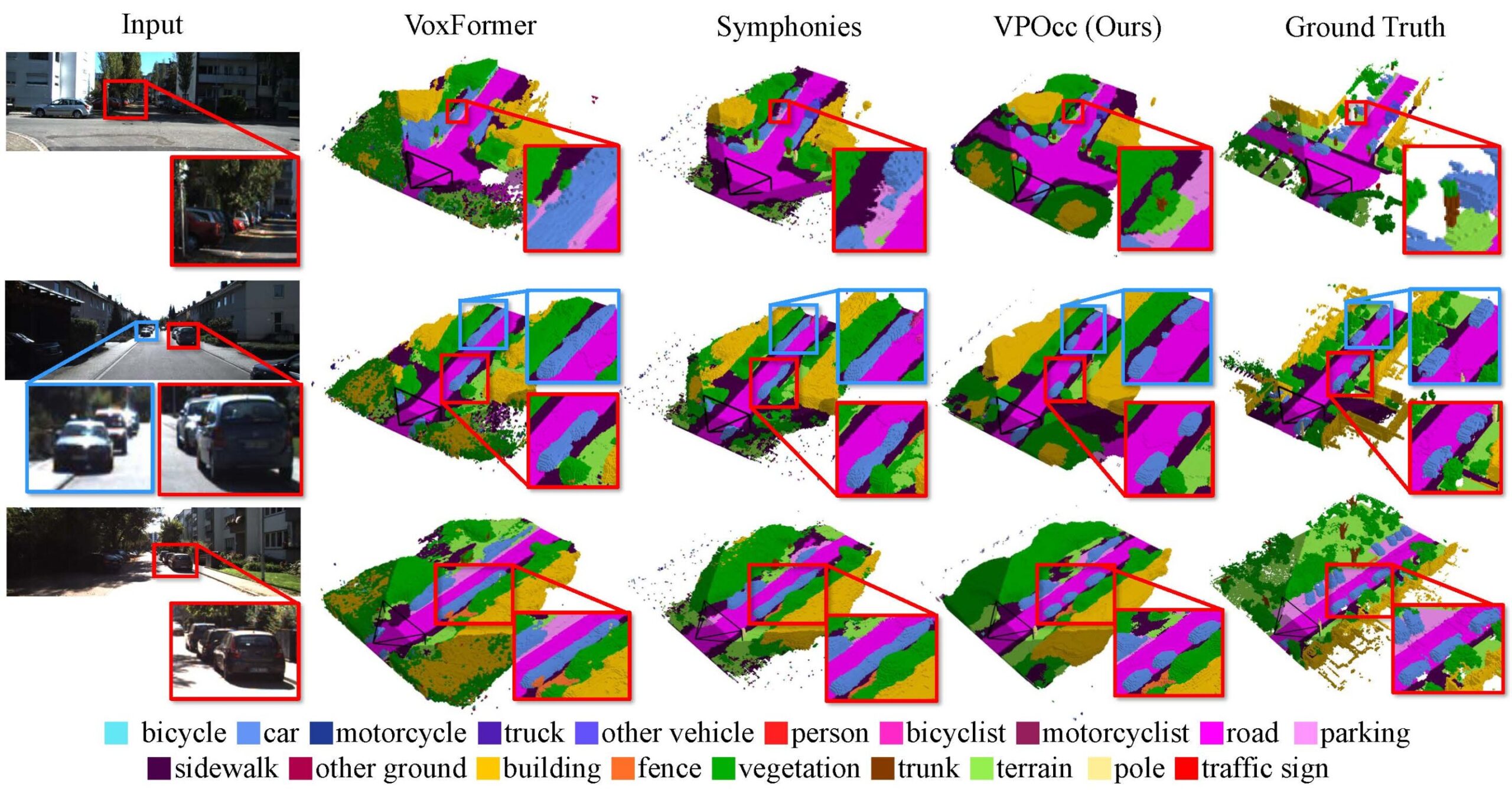
Experimental results demonstrated that VPOcc outperforms existing models across multiple benchmarks in both spatial understanding (measured by mean Intersection over Union, mIoU) and scene reconstruction accuracy (IoU). Notably, it more effectively predicts distant objects and distinguishes overlapping entities—crucial capabilities for autonomous driving in complex road environments.
This research was led by first author Junsu Kim, a researcher at UNIST, with contributions from Junhee Lee at UNIST and a team from Carnegie Mellon University in the United States.
Junsu Kim explained, “Integrating human spatial perception into AI allows for a more effective understanding of 3D space. Our focus was to maximize the potential of camera sensors—more affordable and lightweight than LIDAR—by addressing their inherent perspective limitations.”
Professor Joo added, “The developed technology has broad applications, not only in robotics and autonomous systems but also in augmented reality (AR) mapping and beyond.”
The study received the Silver Award at the 31st Samsung Human Tech Paper Award in March and has been accepted for presentation at IROS 2025 (International Conference on Intelligent Robots and Systems). The paper is available on the arXiv preprint server.
More information:
Junsu Kim et al, VPOcc: Exploiting Vanishing Point for 3D Semantic Occupancy Prediction, arXiv (2025). DOI: 10.48550/arxiv.2408.03551
arXiv
Ulsan National Institute of Science and Technology
Citation:
Renaissance artists’ vanishing points illuminate autonomous vehicles (2025, October 27)
retrieved 27 October 2025
from https://techxplore.com/news/2025-10-renaissance-artists-illuminate-autonomous-vehicles.html
This document is subject to copyright. Apart from any fair dealing for the purpose of private study or research, no
part may be reproduced without the written permission. The content is provided for information purposes only.









